Supervised Learning: Regression
Supervised Machine Learning refers to algorithms that learn x → y or input → output mappings.
You give your learning algorithm examples to learn from, with the right answer (correct y for x), and the algorithm eventually learns to take just the input alone without the output label and gives a reasonably accurate prediction or guess of what the output should be.
Application Examples
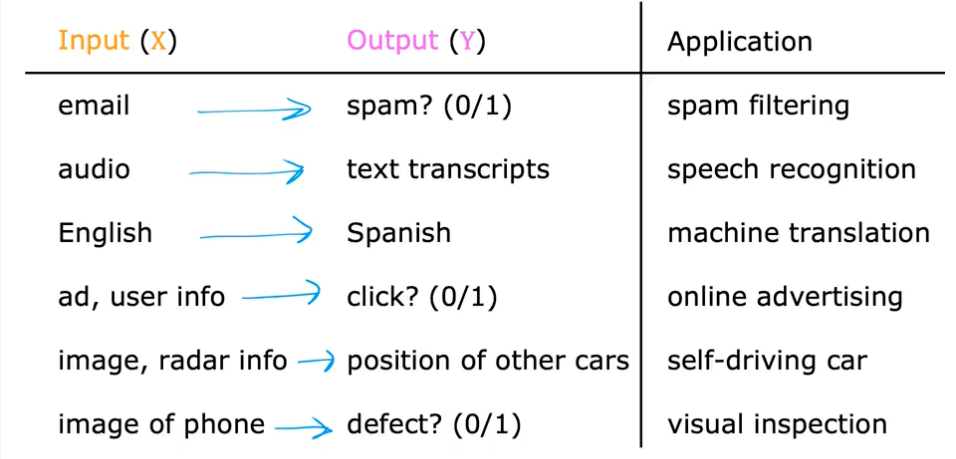
Specific Example: Housing Prices
Say you want to predict housing prices based on house size. You’ve collected some data:
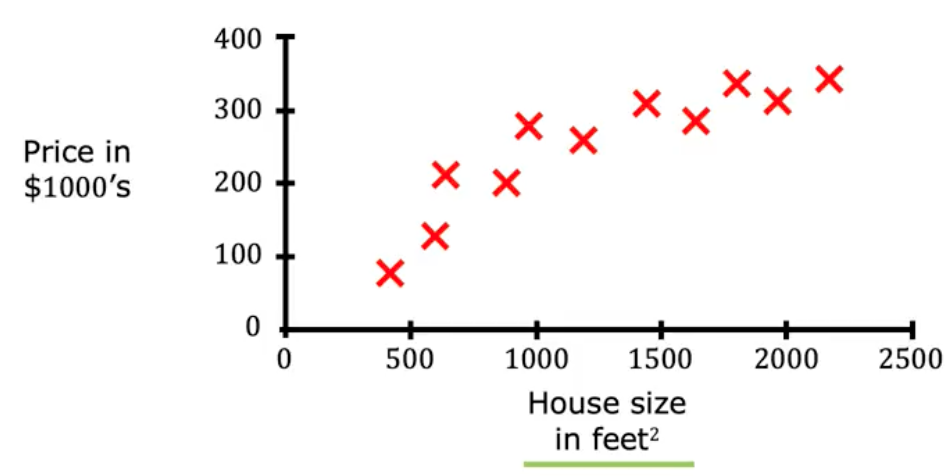
Now your friend wants to know the price of a 750sqft house. How can we help them with our data? Well first we could just use a linear trend line to estimate the value…
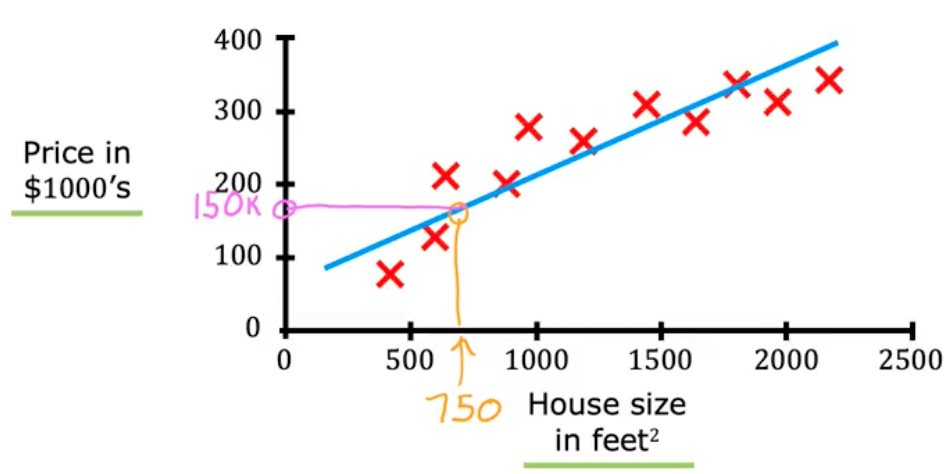
Which looks like it comes out to ~150k. BUT fitting a linear trend line isn’t the only algorithm you can use. There are others that would work better for this application.
For example, you may decide a curve fits better on this data than a linear trend line since it captures more complexity. Well if we decided to use a curve…
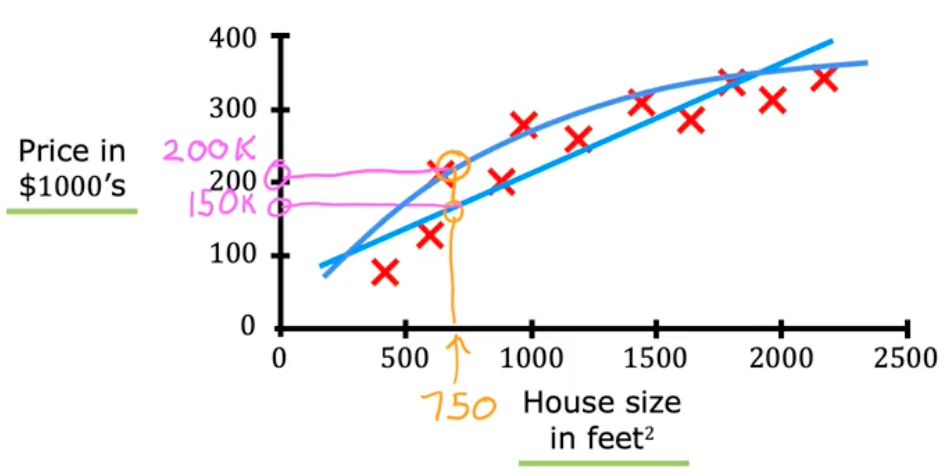
Now your friends same house is predicted to be worth ~200k. Part of being a good machine learning engineer is knowing the best algorithm/function to apply to a subset of data. You can also get an algorithm to systematically choose the most appropriate line or curve or other function to fit this data.
This is supervised learning because you are giving the algorithm a bunch of inputs (house size) and outputs (price), and are asking the learning algorithm to produce more of these right answers.
This housing price prediction is the particular type of supervised learning called Regression (we’re trying to predict a number from infinitely many possible numbers)
Summary:
Supervised Learning = Learning
x→yorinput→outputmappings
Supervised Learning: Classification
There is a second major type of supervised learning algorithm called Classification.
Example: Breast Cancer Detection
Say you are building a machine learning system to detect breast cancer. Using a patient’s medical records your machine learning system tries to figure out if a tumor is malignant (cancerous or dangerous) or benign (non dangerous lump).
Your dataset has tumors of various sizes, labeled with benign: 0 or malignant: 1.
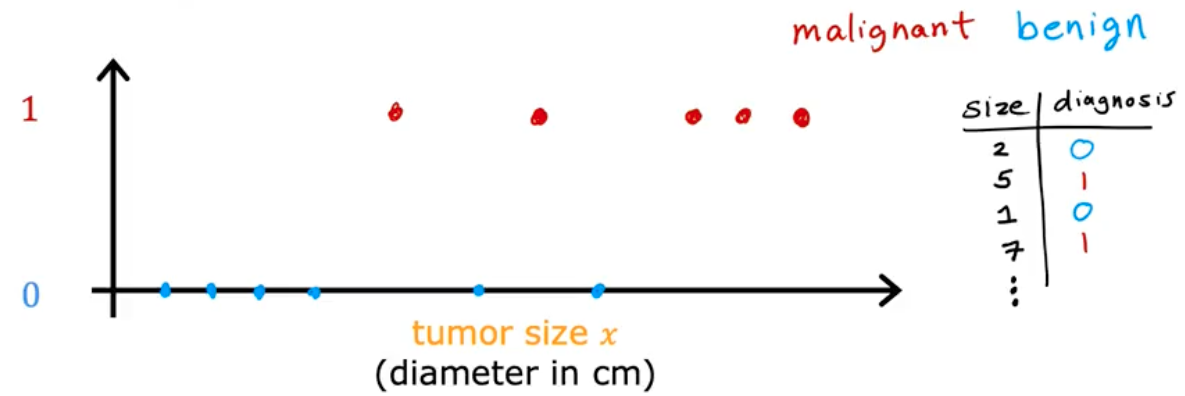
Classification is only trying to predict a FINITE number of possible outputs, in this case two (0 or 1).
This is different from Regression, which tries to predict any number from an INFINITE set of possible outputs
Let’s say you have a patient that comes in with a 7cm lump. Using your machine learning system, how could you predict whether it is cancerous?

This is too simplistic. Thankfully, Classification problems allow you to have more than just two possible output categories. (NOTE: The terms Output Category and Output Class are interchangeable)
So instead, lets have multiple malignant categories that represent different types of cancer diagnoses:
malignant type 1malignant type 2

Classification algorithms predict Categories. Categories can be non-numeric. Like ‘cats’ vs ‘dogs’ Categories could be numbers, but the set of possible output numbers are SMALL and FINITE
You can also use more than 1 input value to predict output categories. In our example, we were only using tumor size. Let’s also use patient age. Now your dataset has 2 inputs.
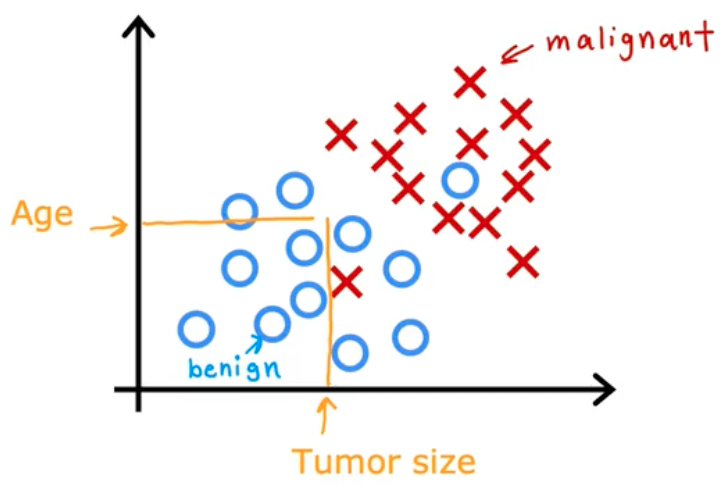
If a patient of a certain age and tumor size was presented (in yellow), how would the Classification algorithm predict the presence of cancer? Given a dataset like this, it could find a boundary that seperates malignant tumors from benign ones. The learning algorithm would be responsible for figuring out this boundary line.
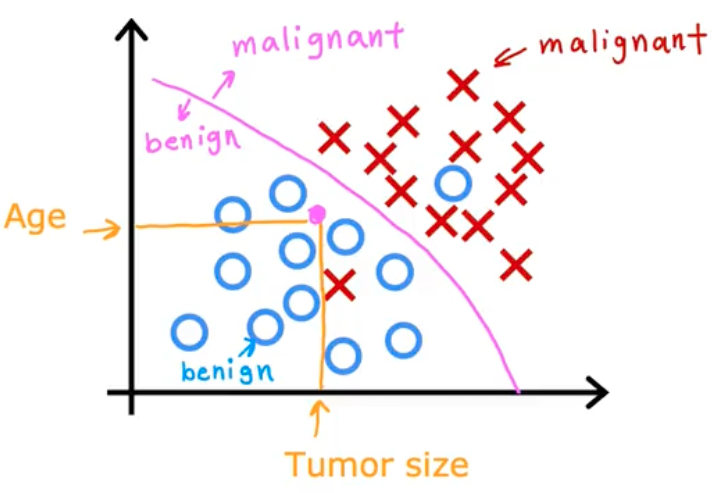
In this case, the tumor is more likely to be benign. This could help the doctor with a diagnosis. In real-world examples, many more input values are required. In this example we could also use the thickness of the tumor clump, uniformity of the cell size, uniformity of the cell shape and so on.
Supervised learning is when we give our learning algorithm the right answer y for each example to learn from. Which is an example of supervised learning: Spam Filtering OR Calculating the average age of a group of customers?
A: Spam Filtering
For instance, emails labeled as “spam” or “not spam” are examples used for training a supervised learning algorithm. The trained algorithm will then be able to predict with some degree of accuracy whether an unseen email is spam or not.
Unsupervised Learning: Part 1
Say you’re given data on patients and their tumor size and the patient’s age. But not whether the tumor was benign or malignant. We’re not asked to diagnose whether the tumor is benign or malignant, because we’re not given any labels (we don’t know the outputs to these inputs). Instead we want to find some structure or a pattern in the data.
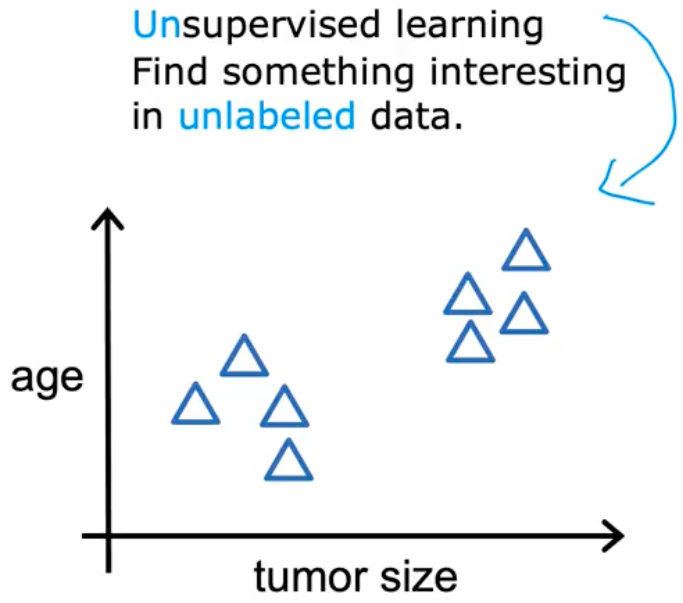
This is known as Unsupervised Learning. We don’t ask it to give us a “right” output for every input. We don’t “supervise” the algorithm.
Clustering
A type of Unsupervised learning method. The algorithm may decide that data can be organized in clusters of data:
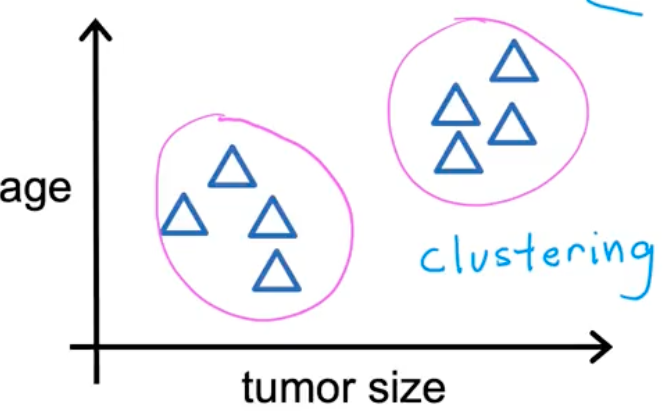
Example: Google News
For example, clustering is used in Google News. They use Unsupervised Learning to look at 1000s of articles every day to find related articles. Notice how in the below screenshot, the clustering algorithm is finding articles with the same keywords
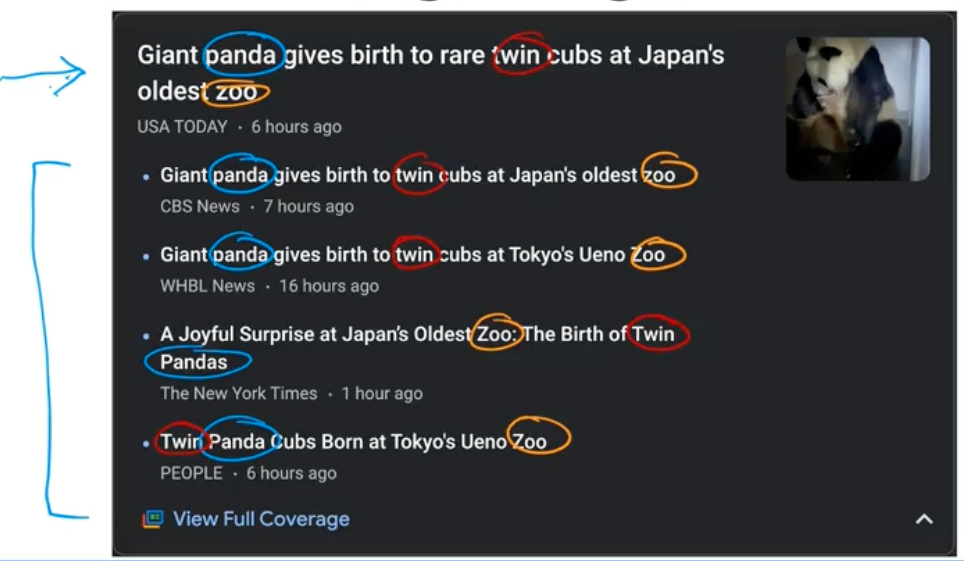
There is no employee at Google telling the algorithm to find the words panda and twin and zoo and put them into the same cluster. Instead, the algorithm finds out without supervision what articles should be added to a cluster on any given day.