A Hugging Face provided introduction to MoE
A Machine Learning technique where multiple expert networks (learners) are used to divide a problem space into homogeneous regions. MoE represents a form of Ensemble Learning. They were also called committee machines.
In recent years, as the leading Deep Learning models used for Generative AI have grown increasingly large and computationally demanding, mixture of experts offer a means to address the tradeoff between the greater capacity of larger models and the greater efficiency of smaller models. This has been most notably explored in the field of natural language processing (NLP): some leading Large Language Models like Mistral’s Mixtral 8x7B and (according to some reports) OpenAI’s GPT-4,2 have employed MoE architecture.
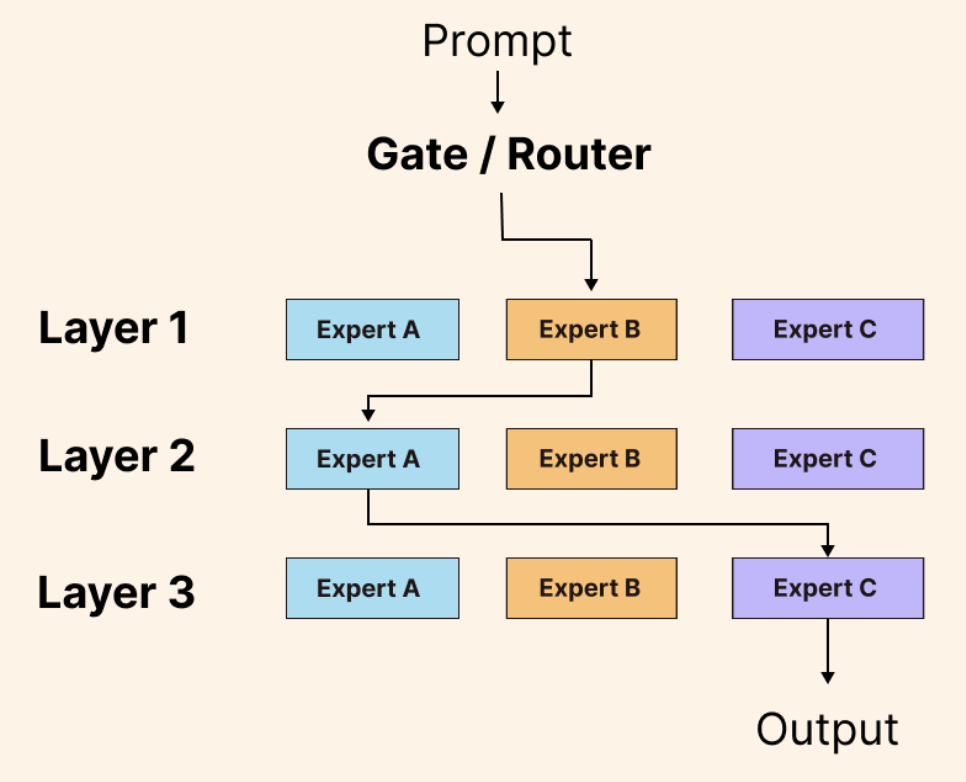
MoE Components:
- Input: This is the problem or data you want the AI to handle.
- Experts: These are smaller AI models, each trained to be really good at a specific part of the overall problem. Think of them like the different specialists on your team.
- Gating network: This is like a manager who decides which expert is best suited for each part of the problem. It looks at the input and figures out who should work on what.
- Output: This is the final answer or solution that the AI model produces after the experts have done their work.