Useful Resources
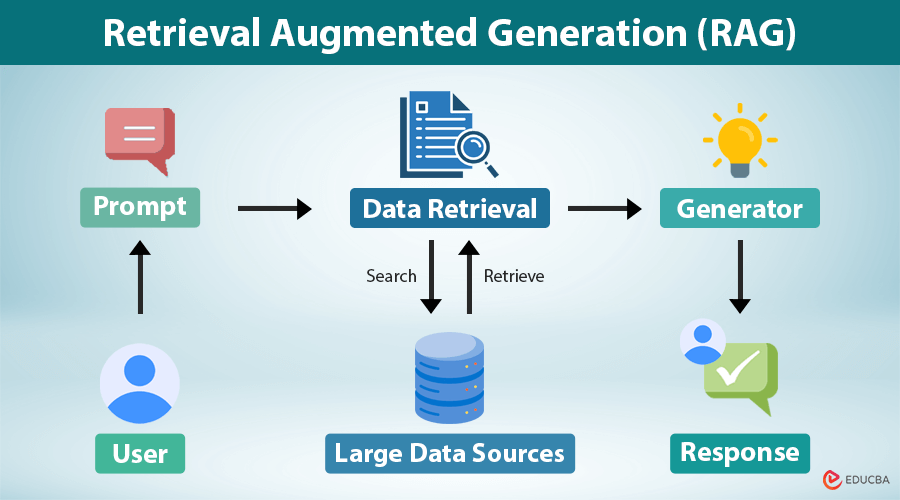
Retrieval-Augmented Generation (RAG) is a technique where external knowledge is retrieved dynamically and combined with an LLM query to enhance the quality of the generated response. It’s particularly effective when the LLM itself does not have enough context or when its general-purpose knowledge needs to be supplemented with specific or up-to-date information.
Example: Law Firm
Say you want to use LLMs at your law firm when doing research and prepping a deck for a specific case. The LLM doesn’t have any context of what has been submitted to discovery for that case, nor does it even know about the case itself. Foundation Models won’t have that data in their training set (rightfully so).
Fortunately, you can leverage RAG to essentially add case discovery documents/data to your LLMs sources of data. Once you have this data exposed to the LLM, the RAG pipeline will automatically search through your discovery documents to find all the data relevant to your query so it can generate the most accurate and appropriate response.