Additional Resources
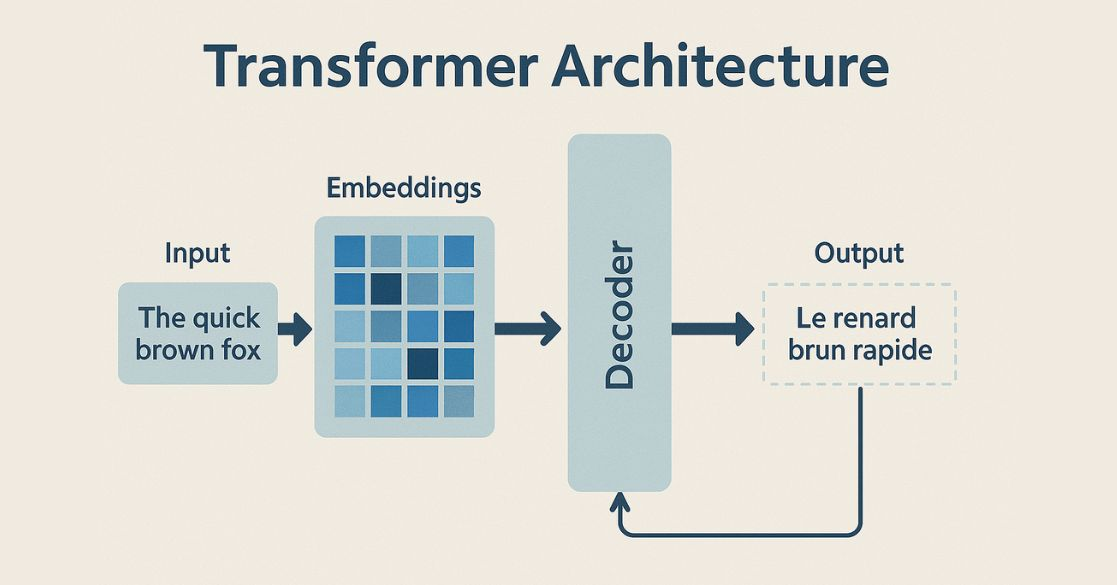
Transformers are a type Neural Network, and a Machine Learning network/architecture. When used, transforms or changes an input sequence into an output sequence. They do this by learning context and tracking relationships between sequence components.
For example, consider this input sequence: “What is the color of the sky?” The transformer model uses an internal mathematical representation that identifies the relevancy and relationship between the words color, sky, and blue. It uses that knowledge to generate the output: “The sky is blue.”
Transformers are mostly used for language models and Natural Language Processing, although there are some Transformers for vision and other areas as well.
Transformer models come in 2 main varieties: encoders (ie. BERT (Language Model)) and decoders (ie. GPT (Large Language Model)), plus hybrid encoder-decoder architectures which mix the two.
- encoders: each word can look at all others (and then decide to which ones it should give more attention)
- decoders: the prediction for each character or word can only look at the previous characters/words.
QKV (Query, Key, and Value) vectors are fundamental to the self-attention mechanism within Transformer models, operating in both the encoder and the decoder.