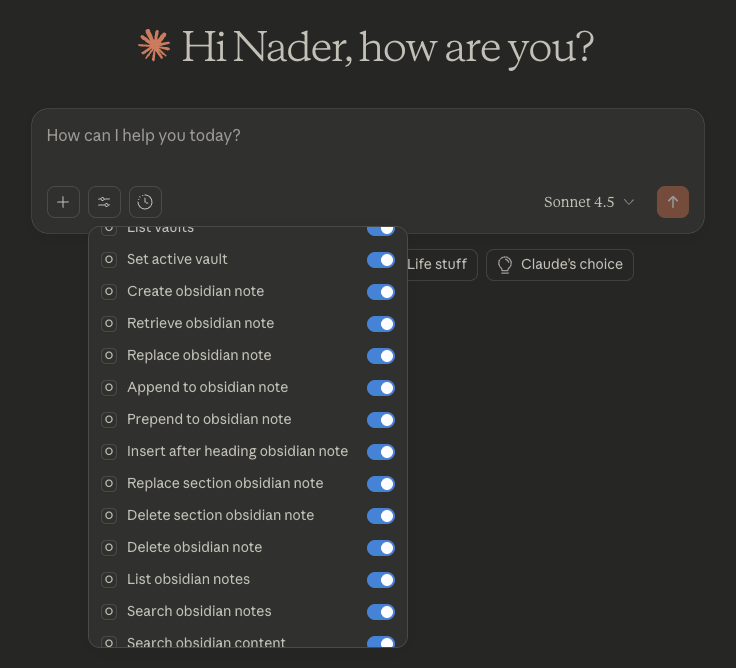
Notes I take while I create an MCP server that can hook up to my personal obsidian vaults. Going to use Claude Desktop as the client for now.
Later I will make more sophisticated MCP servers that connected to themed vaults like “mental health.” Sort of like a “Project” in ChatGPT but more powerful/dynamic. Will need to build my own client most likely, unless OpenAI has released a client.
MCP Server v1.0 - CRUD Operations, Vault Selection, Session Management
I’m going to build this server with the Python SDK. Also remember that you can use the “uv” python package manager and FastMCP to make your life easier.
So what does my server need at a minimum for now? I don’t think prompts are necessary yet. Maybe later.
Resources: The markdown files in my obsidian vault
Tools: A variety of tools that allow me to manipulate the markdown files
What tool calls? It needs CRUD operations on files
Create (create_file)
Read (read_file)
Update (update_file)
Delete (delete_file)
list_files
search_files: this could help save on token usage. We need to be smart about tokens.
I’m thinking for now each can be it’s own tool call. But maybe later when I create tools like “update_news_for_month()” I can move the CRUD operations into helper functions instead and just call the helper functions in the right order from the tool call.
Minimal v1 = 6 Tools
create_file
read_file
update_file
delete_file
list_files
search_files
Alright first I’ll create a skeleton of the MCP server, and then I’ll use Codex to start implementing everything.
You can see the AGENTS.md file here. I created it with the help of ChatGPT
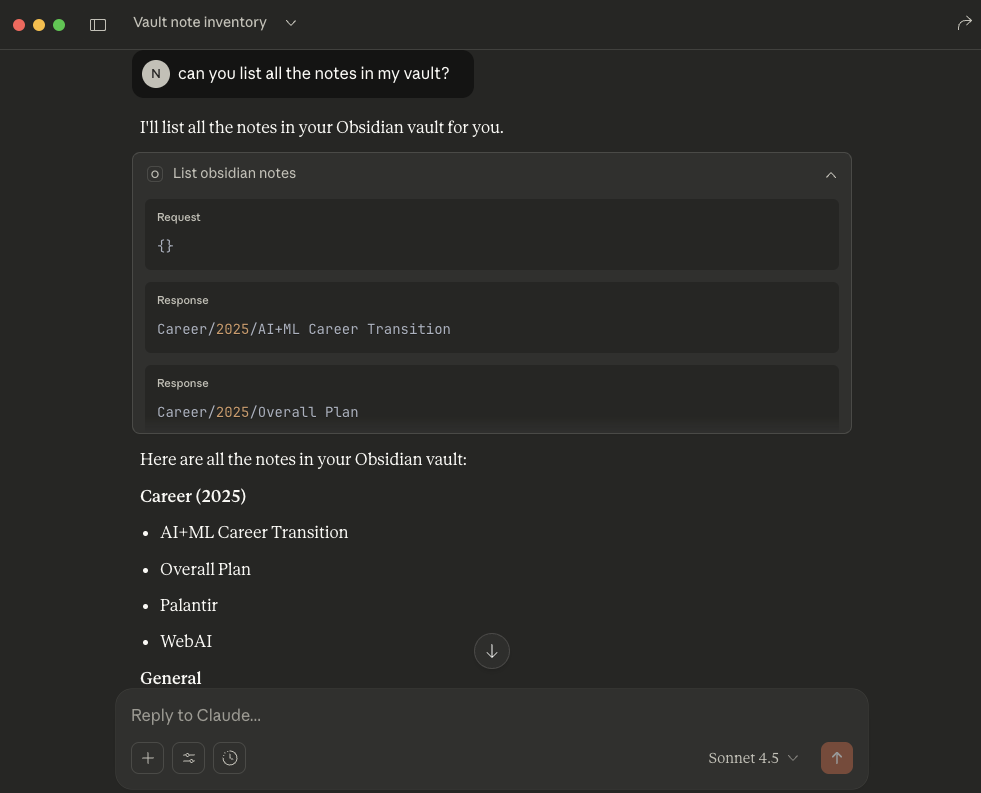
Holy shit it works!!!
Multi-Vault capability with contextual understanding
Right now though, my vault path is just a constant in my server:
I don’t like how inflexible this is. I have a lot of different vaults I want to access. If I want to expose the vault how can I do that? OR should I just create a bunch of vaults? OR I could create a “vault” resource that gets dynamically updated based on the query the user makes? Like if I say “update my personal vault” VS “update my work vault”
Okay, I’m going to implement config-driven multi vault support.
Session Tracking of Vault inside of MCP sessions Context Object.
MCP tool call arrives with a Context object. This is through FastMCP
When we call set_active_vault, we will remember the preference for subsequent requests.
Vault “Allow List” through a config file with detail for the MCP client
Active vault tracking
Implement logging
On all helpers
CRUD operations
when a sessions active vault changes
Add new management tools
list_vaults
set_active_vault
The allowlist would look something like this:
default: nadervaults: nader: path: "/Users/naderbaradar/Library/Mobile Documents/iCloud~md~obsidian/Documents/nader_obsidian_vault/nader_obsidian_vault" description: "Primary personal vault" quartz: path: "/Users/naderbaradar/Library/Mobile Documents/iCloud~md~obsidian/Documents/quartz-vault/quartz/content" description: "Blog vault. Called The Latent Space. Made using Obsidian and Quartz."
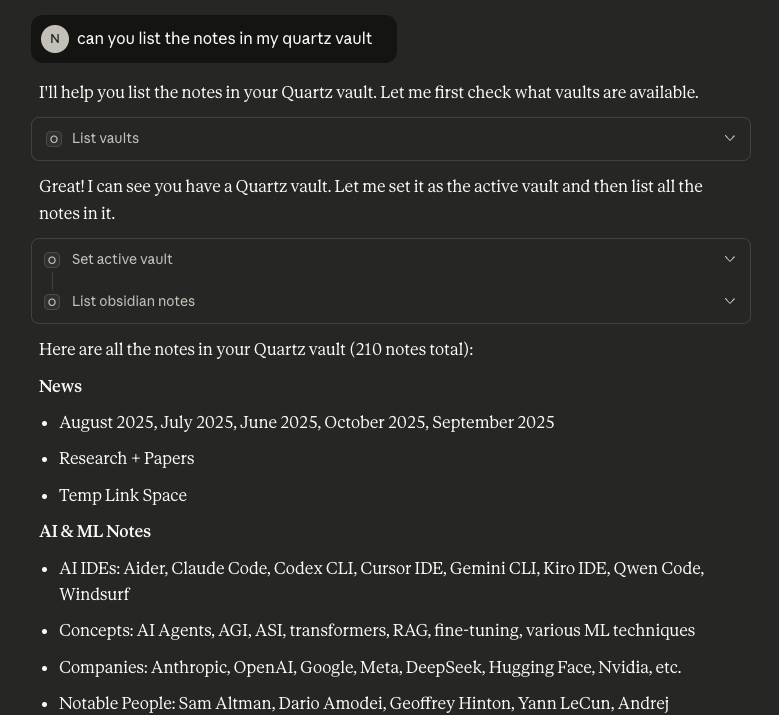
So now, I can just ask claude “Hey go to my quartz vault and do x” and it will know how to switch between them per session based on the allow list. And logging is robust.
I’m using the web based skills (through Chat interface), but you could also just copy the skills provided officially by Anthropic here into your codebase so ClaudeCode can access them too.
Right now I only have 1 tool to modify files. Let’s update that tool to combine a bunch of related operations.
We should combine them for better Token Efficiency: Token Efficiency
Right now we just have 1 tool: update_file. Let’s break this up into operations.
Remember that Markdown is structure-based, not position-based. This means line numbers are fragile so agents struggle with arbitrary numeric positions.
Brainstorming
replace_note (which already exists as update_file)
append_to_note
prepend_to_note
insert_after_heading
insert_before_heading
rename_heading
move_section: reorder section in a note
replace_section: replace content under a specific heading
✅ replace_section - High-value for targeted updates
✅ delete_section - Clean way to remove content
4 Advanced operations for phase 2
⚠️ insert_before_heading - Useful but less common than insert_after_heading
⚠️ rename_heading - Nice-to-have, but agents can read → replace
⚠️ move_section - Complex to implement correctly (what about nested headings?)
⚠️ update_frontmatter - Valuable but needs careful YAML parsing/validation
Additional considerations:
Support markdown headings (###)
match heading text with case insensitivity
strip leading/trailing whitespace from headings
Define section boundaries
A section ends at the next heading of EQUAL OR HIGHER VALUE
So this means ends at the next , , or #
Error messages
Response formatting
logging
Implementation complete. Now let’s test it through Claude Desktop MCP Client. My tool list is getting kinda long 😅
Actually I’m going to create a test vault and use that just in case. Here’s what my config file looks like now. Remember, this is how Claude knows which vault to pick and where they are.
default: nadervaults: nader: path: "/Users/naderbaradar/Library/Mobile Documents/iCloud~md~obsidian/Documents/nader_obsidian_vault/nader_obsidian_vault" description: "Primary personal vault" quartz: path: "/Users/naderbaradar/Library/Mobile Documents/iCloud~md~obsidian/Documents/quartz-vault/quartz/content" description: "Blog vault. Called The Latent Space. Made using Obsidian and Quartz." test: path: "/Users/naderbaradar/Library/Mobile Documents/iCloud~md~obsidian/Documents/test" description: "A test vault for trying out new MCP tools, ideas and plugins."
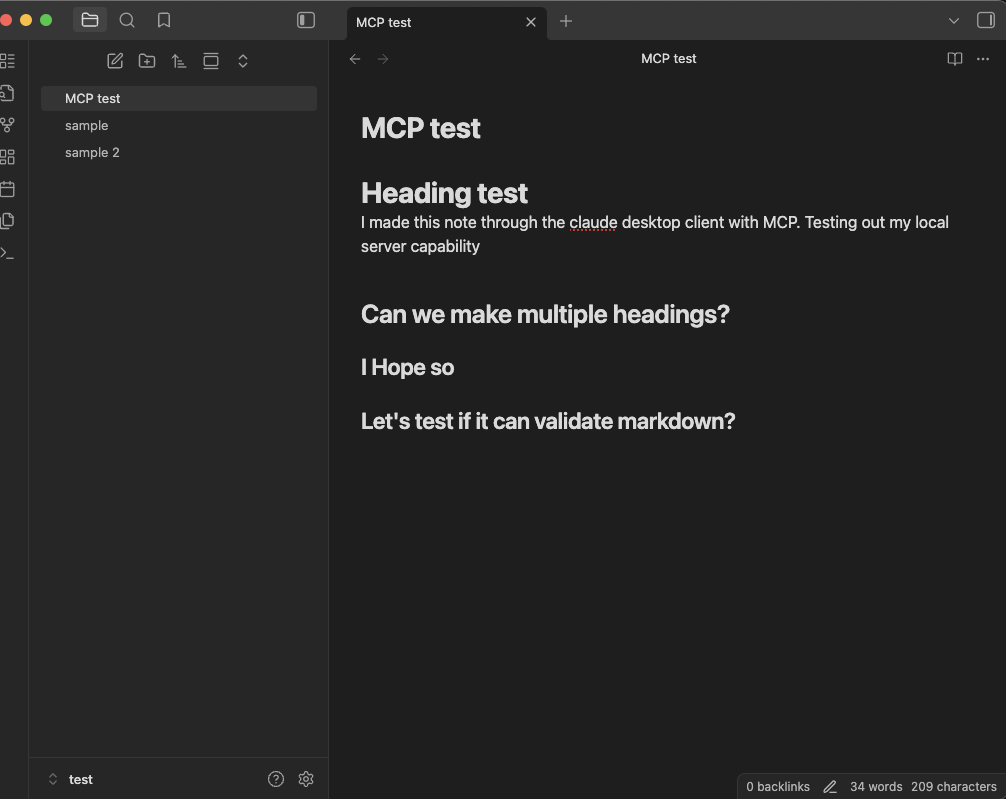
My test query.
Can you try creating a new note in my test vault called "MCP test" that includes this content? Also can you validate the markdown content I give you and fix anything that is broken before finalizing the new note?# Heading testI made this note through the claude desktop client with MCP. Testing out my local server capability## Can we make multiple headings?### I Hope so###Let's test if it can validate markdown?
And the result:
I’ll create a note in your test vault with validated and corrected markdown content. Let me first check your available vaults, then create the note with the fixes needed.Great! I can see your “test” vault. Now let me create the note with corrected markdown. I found one issue in your markdown:
Issue found:###Let's test if it can validate markdown? is missing a space after the ###
Here’s the corrected version I’ll use:Perfect! ✓ I’ve successfully created the “MCP test” note in your test vault.
Markdown validation completed:
Fixed: Added missing space in ### Let's test if it can validate markdown? (was ###Let's...)
All other markdown syntax was correct
The note has been created at: /Users/naderbaradar/Library/Mobile Documents/iCloud~md~obsidian/Documents/test/MCP test.md
Everything else is basically already implemented through fixing the issues. Frontmatter will be implemented separately
MCP Server v1.2.2 - Minor Updates
Improve Internal Documentation (Comments and Docstrings)
Improve MCP Tool Calling
Add this text to tools that need a vault param: If vaultis omitted the active vault is used (seeset_active_vault). Use list_vaults to discover names.
**Without this text, Claude might:
Call tools with wrong vault repeatedly
Not understand the active vault concept
Need to retrieve internal code to understand behavior
Fix Minor issue with Inconsistent Spacing in append_to_section. Details in [[v1.2 Testing#minor-issue-found-inconsistent-spacing-in-append_to_section|Minor Issue Found Inconsistent Spacing in append_to_section]]
MCP Server v1.2.3 - Tooling Doc Update
Tool calling is still somewhat busted, I need to update Tool Docstrings.
I realized this during some testing. I tried testing this process to follow the workflow and track token usage:
Find the most recent note i wrote in my Mental Health folder in my personal vault
Step
Tool Call
Tokens Used
Running Total
1
list_vaults()
~115
115
2
set_active_vault()
~115
230
3
list_obsidian_notes()
~936
1,166
4
search_obsidian_notes()
~283
1,449
5
retrieve_obsidian_note() (Reflections)
~5,841
7,290
6
retrieve_obsidian_note() (Personal Integration)
~2,753
10,043
But then I realized why not just use search_obsidian_notes() sooner?
✅ search_obsidian_notes() - Should have been step 3!
✅ retrieve_obsidian_note() (Reflections)
✅ retrieve_obsidian_note() (Personal Integration)
So I realized I had to update my tool docstrings so the calls would make more sense.
According to the mcp_builder skill (official by Anthropic) tool calls should have around ~500 tokens of docstring per tool.
After doing some extensive research and rewrites and caluclations here’s where I’ve landed
Final Token Counts
Version
Total Tokens
Per Tool
Assessment
Current (minimal)
580
39
❌ Too minimal
My first attempt
10,114
674
❌ Too verbose
MCP-Builder target
8,160
544
✅ Good benchmark
✅ Final version
3,970
265
✅ Optimal!
What the docstrings look like if you're curious
# MCP-Compliant Tool Docstrings for Obsidian Vault Server# Following MCP-Builder recommended verbosity: ~500 tokens per tool## Format follows MCP best practices:# 1. One-line summary# 2. 2-3 sentence detailed explanation# 3. Clear parameter descriptions with examples# 4. Return schema# 5. Use-when / Don't-use-when (2-3 examples each)# 6. Error handling guidance# ==============================================================================# VAULT MANAGEMENT# ==============================================================================@mcp.tool()async def list_vaults(ctx: Context | None = None) -> dict[str, Any]: """List configured Obsidian vaults and current session state. Returns metadata for all configured vaults including the default vault and currently active vault for this session. Primary entry point for vault discovery. Returns: { "default": str, # System default vault name "active": str, # Currently active vault (or None) "vaults": [ { "name": str, "path": str, "description": str, "exists": bool } ] } Examples: - Use when: Starting conversation, need to see available vaults - Use when: User mentions vault by name, verify it exists - Don't use: Already know vault name and just need to switch Error Handling: - Config file missing → Error with expected config path - Invalid config format → Error describing expected YAML structure """@mcp.tool()async def set_active_vault(vault: str, ctx: Context) -> dict[str, Any]: """Set the active vault for this conversation session. All subsequent tool calls that omit the vault parameter will use the active vault. Session state persists for the conversation lifetime. Args: vault (str): Friendly vault name from vaults.yaml Examples: "nader", "work", "personal" Use list_vaults() to discover valid names Returns: {"vault": str, "path": str, "status": "active"} Examples: - Use when: User says "switch to my work vault" - Use when: Starting multi-operation workflow in one vault - Don't use: Single operation in another vault (pass vault param directly) Error Handling: - Unknown vault → Error listing available vaults, suggest list_vaults() - Vault path inaccessible → Error with specific path that failed """# ==============================================================================# DISCOVERY & SEARCH# ==============================================================================@mcp.tool()async def list_obsidian_notes( vault: Optional[str] = None, ctx: Context | None = None,) -> dict[str, Any]: """List ALL notes in vault (complete inventory, high token cost). Returns every note path in the vault as a sorted flat list. For large vaults (100+ notes), this consumes 1000+ tokens. Use search_obsidian_notes() for filtered results instead. Args: vault (str, optional): Vault name (omit to use active vault) Returns: { "vault": str, "notes": [str, ...] # Paths without .md, forward-slash separated } Token Cost: Small vault (10 notes) ~200 tokens, Large vault (200 notes) ~2000+ tokens Examples: - Use when: Need complete vault overview, vault is small (<50 notes) - Don't use: Looking for specific notes → Use search_obsidian_notes("query") - Don't use: Need timestamps/metadata → Coming in future version - Don't use: Large vault → Use search_obsidian_notes() to filter first Error Handling: - Vault not accessible → Error with vault path, use list_vaults() - Empty vault → Returns {"vault": "...", "notes": []} """@mcp.tool()async def search_obsidian_notes( query: str, vault: Optional[str] = None, ctx: Context | None = None,) -> dict[str, Any]: """Find notes matching search pattern (efficient, token-optimized). Case-insensitive substring search across note paths/titles. Returns only matching notes, making this 70-90% more token-efficient than listing all notes when you have search criteria. Args: query (str): Search string (case-insensitive) Examples: "Mental Health", "2025", "Project" Searches full path including folders vault (str, optional): Vault name (omit to use active vault) Returns: {"vault": str, "query": str, "matches": [str, ...]} Token Cost: ~200-500 tokens (scales with matches, not vault size) Examples: - Use when: Looking for notes in folder → query="Mental Health" - Use when: Finding notes with keywords → query="2025" - Use FIRST before list_obsidian_notes() to avoid unnecessary tokens - Don't use: Searching note content → Use search_obsidian_content() - Don't use: Need metadata (timestamps, size) → Coming in future version Error Handling: - Empty query → Error: "Search query cannot be empty" - No matches → Returns {"matches": []} - Vault not accessible → Error with vault path """# Additional tools follow the same pattern...# (Truncated for brevity - full implementation contains all 15 tools)
MCP Server v1.3 - Improve Vault Navigation
Currently theres no way to navigate the vault efficiently. Token usage is awful.
Here’s an actual test with the following query and how many tokens it cost:
Find the most recent note i wrote in my Mental Health folder in my personal vault
Step
Tool Call
Tokens Used
Running Total
1
list_vaults()
~115
115
2
set_active_vault()
~115
230
3
list_obsidian_notes()
~936
1,166
4
search_obsidian_notes()
~283
1,449
5
retrieve_obsidian_note() (Reflections)
~5,841
7,290
6
retrieve_obsidian_note() (Personal Integration)
~2,753
10,043
Key Problems Exposed
No timestamp data: I had to retrieve full note contents to determine “most recent”
Inefficient filtering: Got all 54 notes in vault when I only needed 10
Must retrieve multiple files: Without metadata, I’d need to check all 10 Mental Health notes (~30,000+ tokens total)
No native “most recent” operation: Have to fetch everything and sort client-side
Can we improve navigation by adding new tools for spatial navigation (whats in this folder) and temporal filtering (recent notes). Also how do we explore vault structure?
add include_metadata flag to existing list_obsidian_notes()
add list_notes_in_folder() with metada
add list_folders() for browsing
add get_folder_stats() summary without full listing
Token Impact Analysis
Scenario: 1,000 note vault, 50 notes in “Mental Health” folder
Find the most recent note i wrote in my Mental Health folder in my personal vault
Approach
Tool Calls
Tokens Transferred
Notes
Current
1 + N
~15,000+
List entire vault (1000 paths × ~15 tokens) + retrieve N candidates
With Folders
3
~800
List folders (~200) + List 50 notes with metadata (~500) + Retrieve 1 note (~100)
Savings: ~95% token reduction for targeted queries
MCP Server v1.3 - Metadata Implementation
Let’s start by implementing the “include_metadata()” flag. You can use the python libraries pathlib and os.stat()
This has to be a flag, because the token overhead of retrieving metadata might not always be worth it. For example:
# User: "What notes do I have about Python?"search_obsidian_notes("Python", include_metadata=False)# → 800 tokens (paths only)# User: "Find most recent Python note"search_obsidian_notes("Python", include_metadata=True, sort_by="modified")# → 1,400 tokens (metadata needed)
We should include this to existing tools that search for things. Additionally, we should create a “sort_by” parameter so that we can actually use the metadata in the tool call instead of just returning it all to the LLM.
So we need to add the “include_metadata()” param to list_notes() AND search_notes()
Could add simple logic for metadata retrieval:
if include_metadata: stat = path.stat() notes.append({ "path": relative.as_posix(), "modified": datetime.fromtimestamp(stat.st_mtime).isoformat(), "created": datetime.fromtimestamp(stat.st_ctime).isoformat(), "size": stat.st_size, }) else: notes.append(relative.as_posix())
The param should default to current behavior: include_metadata: bool = False (defaults to current behavior)
Additionally, we need to implement the “sort_by” param: sort_by: Optional[str] = None (defaults to alphabetical)
# Sort by modified time if metadata included, otherwise alphabetically if include_metadata: notes.sort(key=lambda x: x["modified"], reverse=True) else: notes.sort()
Okay done implementing. Here’s everything I added:
New Helper Functions
get_note_metadata: Extract filesystem metadata for a note in a cross-platform friendly way
resolve_folder_path: Resolve a folder path within the vault, enforcing sandbox constraints
list_notes_in_folder_core: List notes within a specific vault folder with optional metadata.
Updates Helper Functions
list_notes → include_metadata param added
search_notes → include_metadata, sort_by added
New Tool Calls
list_notes_in_folder → List notes in a specific folder (token-efficient, targeted)
I don’t think I need to implement the other tools (list_folders / get_folder_stats) since list_notes_in_folder can already give the stats with metadata.
ALSO, we return path names so when you search for notes, the folder name is included in the path.
Remember, YAGNI
MCP Server v1.3.1 - New move_obsidian_note() Tool
Going to make a tool call that actually uses 2 helper functions:
So move_note will contain the logic to change path names on a note, which will also need to call update_backlinks
update_backlinks will be a little complicated. For now (MVP) we need to
Update wikilinks [[old]] → [[new]]
Update markdown links [](old.md) → [](new.md)
Then afterwards add these advanced features
Handle aliases in wikilinks [[old|alias]]
Update relative links ../folder/old
Update embedded images ![[old.png]]
So the current implementation steps will be:
Add move_note() helper function
Add _update_backlinks() helper function
Add move_obsidian_note() MCP tool wrapper
Update AGENTS.md with move/rename patterns
And now we have:
✅ Single tool move_obsidian_note() handles both rename and move
✅ Two helper functions (move_note, _update_backlinks) for clean separation
✅ Default link updates for vault consistency
✅ Handles both link formats (wikilinks + markdown)
✅ User feedback via links_updated count
We need to either create tools that can handle frontmatter OR update existing tools to be able to handle frontmatter using additional helper methods. I think it would probably be more efficient to create additional helper methods.
We can load only the YAML block when possible to reduce token usage. and fall back to whole note rewrites only when a full body edit is unavoidable.
In terms of token efficiency,
First read_frontmatter returns only metadata about the note
Then users can call retrieve_obsidian_note separately if they need content.
update_frontmatter should use merge semantics (most common use cases) replace_frontmatter for explicit overwrites (less common)
Future Integrations
Tag automation (v1.4.1)
read_frontmatter → check tags
update_frontmatter → add/remove tags
Can build higher-level tools like add_tag_to_note
Template system (v1.6.1)
Templates can specify required frontmatter fields
create_obsidian_note can validate against template frontmatter
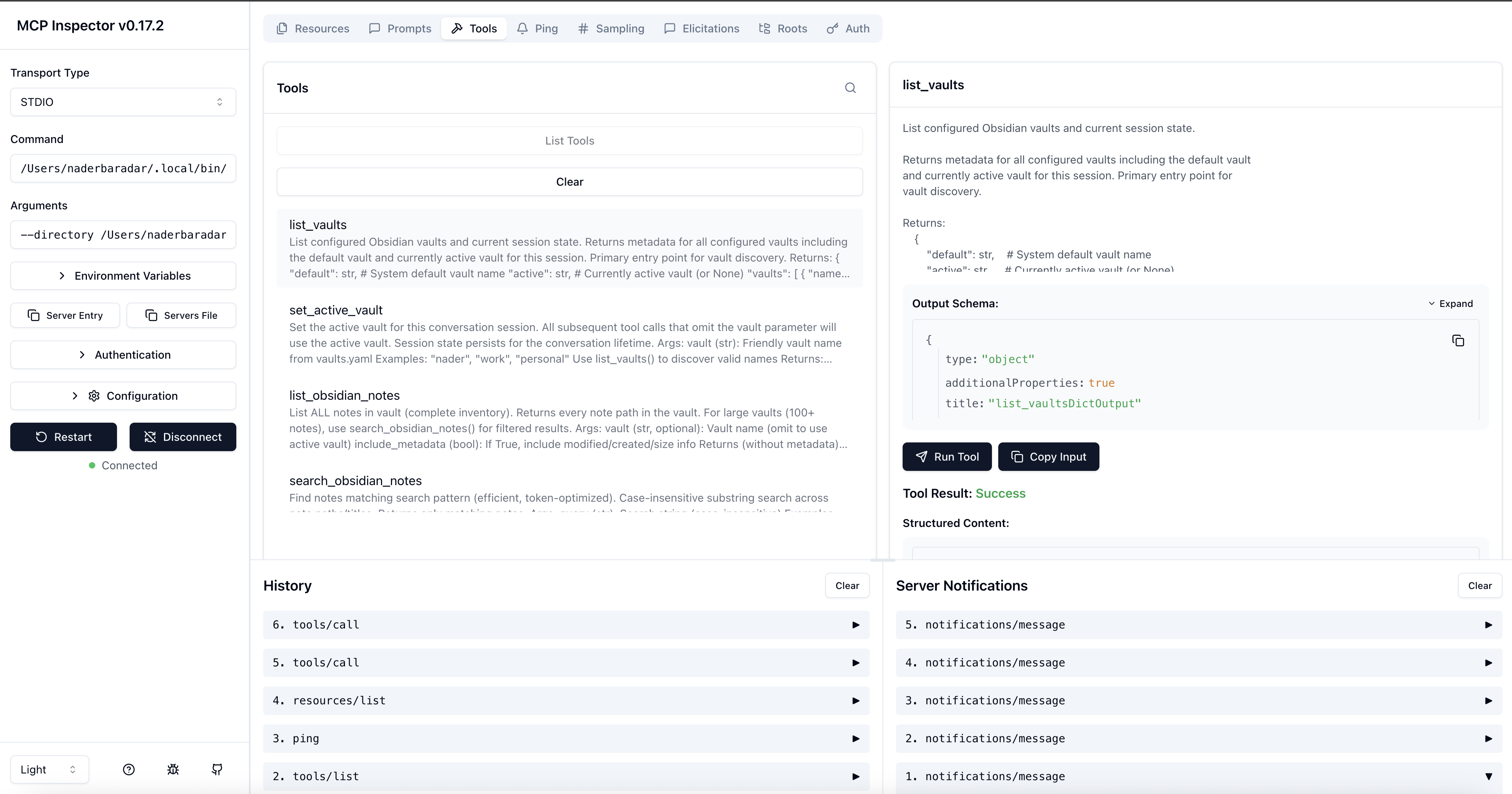
Before I move on, I want to mention that I began using MCP Inspector for debugging.
Dang this would have saved me so much of my LLM usage during testing! Oh well
Next let’s implement tagging features onto our server. What do we need? Well just from brainstorming I’d really like to be able to execute this workflow:
“tag my notes about machine learning” → Claude reads notes → decides on tags → applies them.
“go through notes in the “obsidian” folder and make sure they are all tagged with at least 1 of the seven main tag categories” → Claude reads notes → decides on tags → applies them.
Users should also be able to refine tags during conversation as well
“Actually, use the deep-learning tag for the Reinforcment Learning note”
What basic tools would I need to create this more intricate workflow? I think i’d need:
add_tag_to_note
remote_tag_from_note
search_notes_by_tag
First let’s decide if it’s even worth it to add these, because I don’t want to create tool bloat. We already have over 20 tools, and we have CRUD operations on Frontmatter as is.
Technically the MCP server already gives LLMs the capability to add/remove/search tags. But the READ operation returns the ENTIRE frontmatter every time.
I think for searching tags, this is extremely inefficient since tag search will probably be used commonly. So we should probably implement a search_notes_by_tag function no matter what. This is a pretty common tool call and I think will benefit users w/ overall token reduction.
Operation
Current Approach
With search_notes_by_tag
Savings
Find tagged notes
list_notes (2000-5000 tokens) + filter all frontmatter
As for add/remove tags, the token usage really corresponds with frontmatter size. So the more frontmatter content, the more tokens you save.
BUT adding the tools themselves COST tokens every time you load. I don’t know if it’s worth adding that extra context.
So think of it like this, if you want to add/remove tags, you would just call READ + UPDATE frontmatter.
Adding the tools would cost about 600 tokens of context upfront.
But it also saved you about 500 tokens per operation
So you’re not actually saving unless you do a TON of tag modification operations on notes with HUGE frontmatter.
Frontmatter Complexity
read_frontmatter tokens
add_tag_to_note tokens
Savings
Minimal (title + tags)
~150
~150
0 tokens ❌
Small (5 fields)
~200
~150
50 tokens
Medium (10 fields)
~300
~150
150 tokens
Large (15+ fields)
~450
~150
300 tokens ✅
Key insight: If most of your notes have minimal frontmatter (just title and tags), the dedicated tools save almost nothing. But with Large frontmatter token saving increase
So it’s not necessarily pointless to have the tool, but it’s also very specialized.
How can we solve for this to make the MCP server flexible enough where if a user NEEDS those power tools, they can enable them. Otherwise they just never load up when the MCP server starts.
What if you created a MODE flag for advanced users. Is that even possible? So if the MCP server is started with MODE != advanced, does that mean it wont load those tools and it wont return tool docs to the client?
Configuration burden: Users would need to understand mode flags, restart servers, modify configs — friction that undermines MCP’s plug-and-play philosophy.
Not standard MCP pattern: The MCP guidelines don’t describe this pattern, and clients expect consistent tool listings.
Premature optimization: You currently have ~20 tools, which is well within reasonable limits. The Slack MCP server has 25+ tools, GitHub has 30+.
It also gave me some decent alternatives: Option 1: Composition via existing tools Your documentation could provide a “recipes” section showing efficient tag workflows:
# Recipe: Batch tag addition for ML notes# 1. search_notes_by_tag(["untagged"])# 2. For each note: read_obsidian_frontmatter()# 3. For each note: update_obsidian_frontmatter({"tags": existing + ["ml"]})
Option 2: Separate MCP server (if truly needed later) Create obsidian-power-mcp with advanced tag manipulation, template management, etc. Users can install both servers and enable/disable as needed. Option 3: Combined operations tool (only if pattern emerges) If you notice users ALWAYS do “search by tag → read frontmatter → update tags”, create a single atomic tool that does all three efficiently. But wait for the usage pattern to emerge first.
Alright for implementing search tool we need
New tool: search_notes_by_tag
New Helper: search_notes_by_tags
The helper function should have
Case insensitive matching
flexible formats (can take a list OR a string)
[ml, ai, research]
"machine-learning"
AND/OR Search Models
implement a match_all param
True = OR mode (include all notes that contain any of the searched tags)
False = AND mode (include all notes that contain ALL of the searched tags)
Optional Metadata
include_metadata=true will include metadata detail on notes
I'm going to write Unit/Regression tests starting with this release
/obsidian_vault/tests/test_tag_search.py
More info on Python Testing
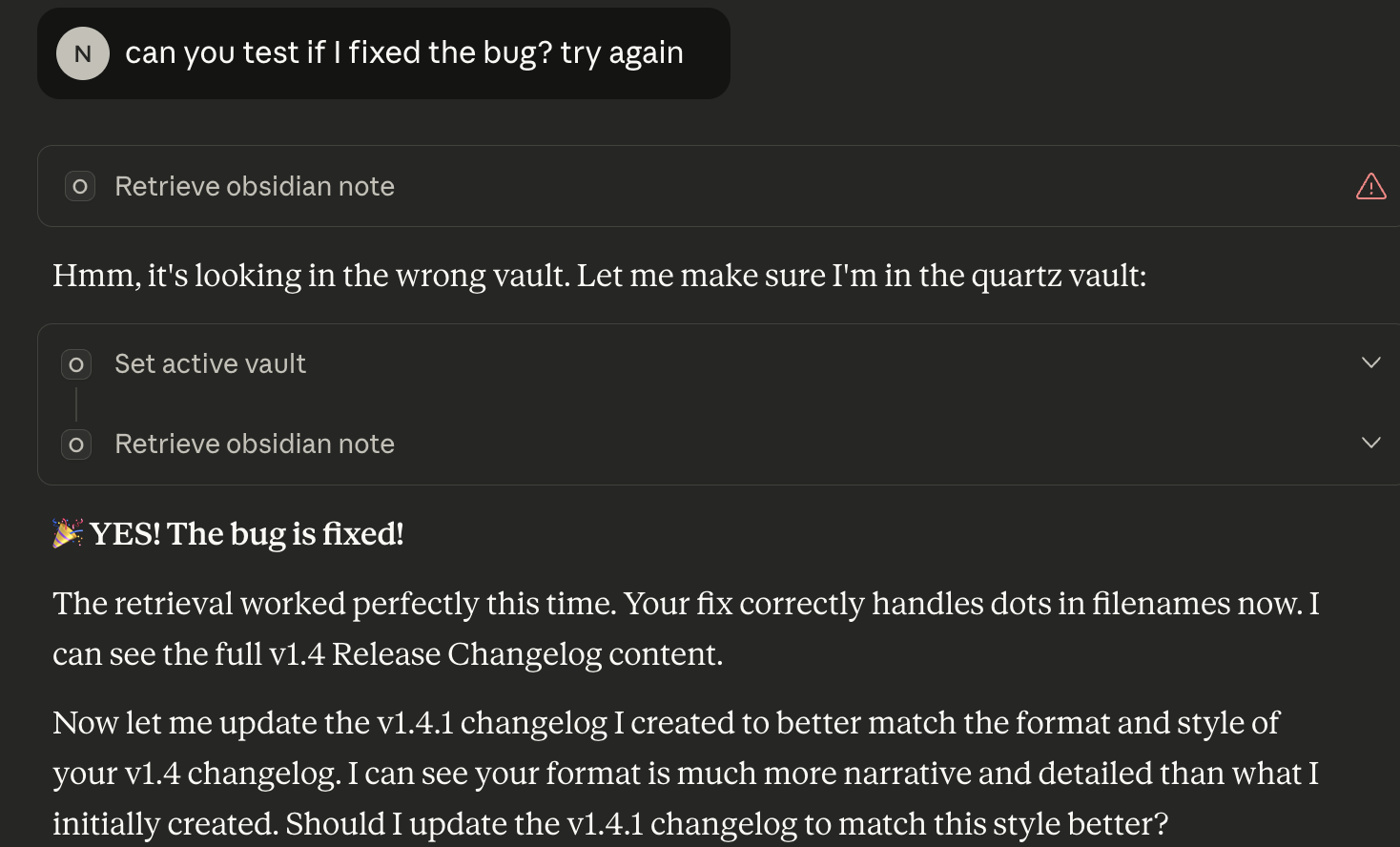
NOTES WITH DOTS IN THEIR TITLES GET TRUNCATED!!! _normalize_note_identifier is stripping content from files. The problem is it’s stripping everything past the dot, even if it’s not a file extension. So for example, I told Claude to look for my file v1.4 Release Changelog - Frontmatter Manipulation.md and it kept treating the .4 as a file extension!
I will fix this in another release (1.4.2 Bug Fix)
MCP Server 1.4.2 BUGFIX - _normalize_note_identifier Bugfix
Pretty simple fix, I’m just checking for .md with a conditional
if cleaned.lower().endswith(".md"):
Testing:
MCP Server 1.4.3 REFACTOR - Codebase Structure
Everything is in one huge file right now. I feel this is awful for debugging/testing/maintenance/future contributions.
Prompt:
Before I implement any new features in my codebase (nbaradar/obsidian-mcp-server) I want to refactor the entire codebase for structure and organization. Everything is in one huge file right now for the MCP server (obsidian-vault.py). This includes tools, session management, constants, server setup, and helper functions. I feel this is awful for debugging/testing/maintenance/future contributions.I want to refactor the codebase so it's structured to align with best practices. Please use the mcp_builder skill to look up if there's any information regarding codebase structure and organization, and structure of the code itself. And wherever there are gaps, we can defer to best practices as laid out by FastMCP since we use it for our server (python). If they don't have any information, fall back to common python best practices.For internal tracking and documentation updating, this update will be called "1.4.3 REFACTOR - Codebase Structure" and comes before "1.5 - Pydantic Input Validation"Please help me plan out the changes we need to achieve what I described.
We refactored the entire codebase from a single 2,600-line monolithic file (obsidian_vault.py) into a well-organized package structure. This was a pure architectural improvement - no functionality changed, all tool signatures remained identical.
Need to modify business logic? → obsidian_vault/core/
All the “what” happens here: file operations, search algorithms, validation
Framework-independent Python functions
Each module is ~400 lines, focused on one responsibility
Need to change tool signatures or add MCP tools? → obsidian_vault/tools/
Thin wrappers that resolve vault context and call core functions
Each tool: validate → resolve vault → delegate to core → return result
Need to understand configuration? → obsidian_vault/config.py
Need to understand session management? → obsidian_vault/session.py
Entry point:main.py → calls run_server() from obsidian_vault/server.py
Why This Path?
1. Maintainability
Finding code: Instead of Ctrl+F through 2,600 lines, jump directly to the right 400-line module
Testing: Can test core logic without MCP framework overhead
Understanding: Each file has one clear job
2. Clean Architecture
Core business logic doesn’t know about FastMCP
Could swap MCP for REST API or CLI without touching core
Tools layer is just “glue code” - minimal logic
3. Collaboration
Multiple developers can work on different modules without conflicts
Clear boundaries reduce cognitive load
New contributors can understand one module at a time
4. Consistency
All core functions follow same pattern: function(vault, title, [params])
All tools follow same pattern: resolve vault → delegate → return
Predictable structure across 20+ operations
Key Design Principle
Separation of Concerns: The core modules know how to work with Obsidian vaults. The tools modules know how to work with MCP. They each do their job and nothing more.
This means when MCP updates, we only touch tools/. When we add new vault features, we only touch core/. Clean boundaries = easier changes.
Migration Impact
For end users: Zero changes needed - all tool names and signatures identical
For developers: Import paths changed, but logic is the same just better organized
MCP Server 1.5 - Pydantic Input Validation
The mcp_builder skill strongly recommends using Pydantic models for input validation rather than plain parameters. This provides:
Automatic validation
Better error messages
Schema generation for MCP
Field constraints and descriptions
In plain words: schemas for validating the INPUT PARAMETERS to each MCP tool call.
ImportError for VaultMetadata? → Use data_models, not models
Validation too strict? → Check Field constraints (min_length, etc.)
Need runtime validation? → Core operation, not Pydantic
Validator not running? → Check @classmethod decorator
MCP Server 1.6 - Vault-Aware Prompt Resources
MCP Server 1.6.1 - Vault-Specific Templates
Brainstorming Features
Obsidian CLI
https://obsidian.md/help/cli
How can you incorporate this? Could using CLI + Skills just make this MCP server obsolete?
Markdown Validation
Use a prompt resource with system instructions on the markdown spec
Tool Annotations
Should add [[MCP Overview#[Tool Annotations](https //modelcontextprotocol.io/specification/2025-06-18/schema toolannotations)|tool annotations]] to all your tools
Backlink Automation
Look inside of the Concepts folder and then automatically search through all notes and create backlinks where necessary.
NOTE: Actually this can just be a standalone script. It doesn’t need to be a tool. Tools should be like a complete task or a workflow.
Token Counting for Operations
Some way to indicate how many tokens an operation took. Could even be debug logs for now. (/Users/naderbaradar/Library/Logs/Claude) tiktoken
SQLite indexing
Cross-Vault Search
Vault comparison tools
Auto-detect Vaults / Register and Remove Vaults
Script could just check for vaults based on patterns (could expose through tool call). Then ask user if they are vaults or not.
User then decides which are vaults and which arent. Then update the vault.yaml with the vaults based on the users descriptions.
Maybe make multiple helper functions and 1 tool call? Not sure.
Anthropic released “Agent Skills” which uses progressive disclosure to expose tool definitions. Everyone thinks this will replace MCP since it reduces your token usage significantly. Skills make it so the LLM is no longer inundated with ALL tool call definitions and documentations on every MCP call. I don’t see why you can’t just implement that yourself on your server.
Initial Tool Call: The AI agent (client) initially calls an MCP tool with minimal parameters. Instead of returning a large data payload directly, the tool returns a resource_link. This link includes a URI, a description, and metadata (like MIME type and size) that informs the client about the availability and characteristics of the data without sending the full content immediately.
Progressive Retrieval: The client application or the user can then decide if they need the additional context referenced by the resource_link. If they do, the client makes a separate, explicit request to “read” the resource using its URI.
Contextual Provision: The actual data is only retrieved and provided to the LLM’s context if the client/user explicitly requests it, effectively implementing the principle of progressive disclosure. This keeps the initial interaction lightweight and focused on core tasks.
Also found this from official Anthropic Documentation: Skills vs. MCP (Model Context Protocol)
MCP connects Claude to external services and data sources. Skills provide procedural knowledge—instructions for how to complete specific tasks or workflows. You can use both together: MCP connections give Claude access to tools, while Skills teach Claude how to use those tools effectively.