Quantization is a technique to reduce the size and computational demands of Large Language Models by representing their weights and activations with fewer bits.
This helps to
- Reduce Model Size: Reduces number of bits needed, shrinking overall LLM size
- Improve Performance: Uses lower precision data-types (INT8 or INT4 instead of FP32)
- Enhance Accessibility: Enables running large models on devices with limited memory and processing power.
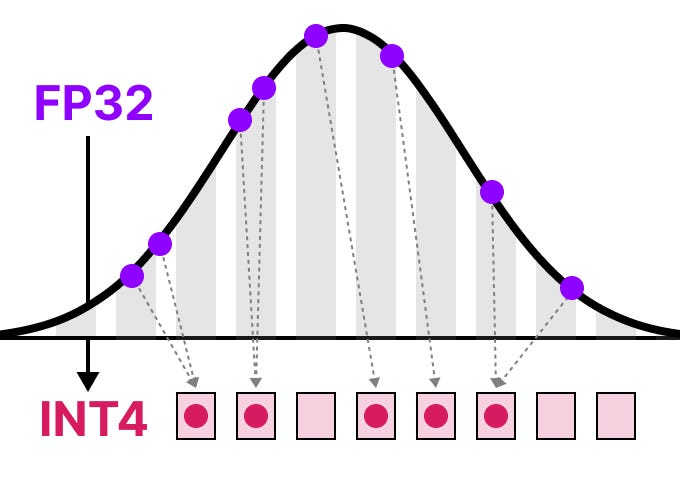
for in depth guide: https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-quantization