These are my current Desktop Specs, updated July 2025
For us, the best option is the use text-generation-webui. This is so we can take full advantage of our GPU and RAM.
TL;DR for You
Given your 3080 Ti (12GB VRAM), you’ll likely:
- Use GGUF (quantized) models for 13B or larger models
- Use safetensors/PyTorch for 7B full-precision models or advanced features
First lets choose a good model, then install WebUI with CUDA and GGUF support, then Load and run the model.
Choosing the Model
Hmm is there a way I can simplify it in my head like okay this Full Precision model is 13B. I have 12 VRAM on my 3080ti, so how do I know if I can run the 13B on 12 VRAM?
If I can’t, then I think to myself okay well I have 96gb of RAM so I can run it with Quantization. if I run 13B FP at q4_k_m how much memory will I need and do I have enough RAM?
Here’s how you can break it down:
Mental Model: Can I run this Model?
Step 1: Start with the Model Size
- 13B = 13 billion parameters
- More params = more memory needed
Step 2: Can this fit in my GPUs VRAM?
⚠️NOTE: If it barely fits, some backends (like llama.cpp) will offload extra layers to CPU RAM automatically.
| Quant Level | VRAM (13B) | VRAM (7B) | Notes |
|---|---|---|---|
| FP16 (full) | ~24GB | ~13GB | ❌ Too much for your 3080 Ti |
| Q8_0 | ~16–18GB | ~9–10GB | ❌ 13B won’t fit |
| Q6_K | ~13–14GB | ~7GB | ❌ 13B right on the edge |
| Q5_K_M | ~10–11GB | ~6GB | ✅ Fits in 12GB (just barely) |
| Q4_K_M | ~8–9GB | ~4.5GB | ✅ Safely fits |
| Q4_0 | ~7–8GB | ~4GB | ✅ Easily fits |
More information on LLM Memory Usage
Step 3: If it doesn’t fit in VRAM, use RAM
Since we have 96GB memory, we should use GGUF. Whenever a quantized model exceeds VRAM, it offloads the excess to RAM.
Rule of Thumb:
- GGUF Q4/Q5 13B model → needs ~10GB VRAM
So based on everything I know, I want to run something easy for now. Like a 16FP 13B param model (which needs 26GB VRAM), but Quantized with Q4_K_M GGUF so .33 of 26GB which is ~8.5GB VRAM. So I should be totally fine and I have overhead. Then after that, I’ll move up to Q5.
Model Overview
Here's the Model I chose
Download Link for Q4_K_M Quant (11.3GB)
Name: Llama-3.2-8X3B-MOE-Dark-Champion-Instruct-uncensored-abliterated-18.4B-GGUF
Type:
- Mixture of Experts (MoE): Uses 8 x 3B models — but only a subset is active per token
- Params: 18.4B total, but fewer are used per forward pass
- Architecture: LLaMA 3.2 MoE
- Context length: 128k (!!) — excellent for long-form generation
Mixture of Experts (MOE) don’t activate all the parameters at once. Instead
- They load all “experts” into memory
- then only 2-4 of them are used at a time per token

💡 That means you get big model performance without full big model cost.
So this 18.4B MoE model behaves more like an ~6–7B active model per token in terms of VRAM use.
Setup Dev Env
Creating a dedicated folder on C for now: C:\LLM\webui
You need to
- Install Python
- Install Git
- Clone text-generation-webui
- Download the model
- Install dependencies
- Launch WebUI
I need to install python, I’m going to try using the Python Install ManagerWorked. That was easy.
For text-generation-webui to work it matters where you put the model. You need to place it here:
text-generation-webui\user_data\models\I placed mine here: C:\LLM\webui\text-generation-webui\user_data\models\Llama-3-DarkChampion
Start the Model w/ The UI
Then finally start the WebUI with
.\start_windows.batAnd navigate to: http://localhost:7860
Once there, go to the “model” tab on the left and load your model…
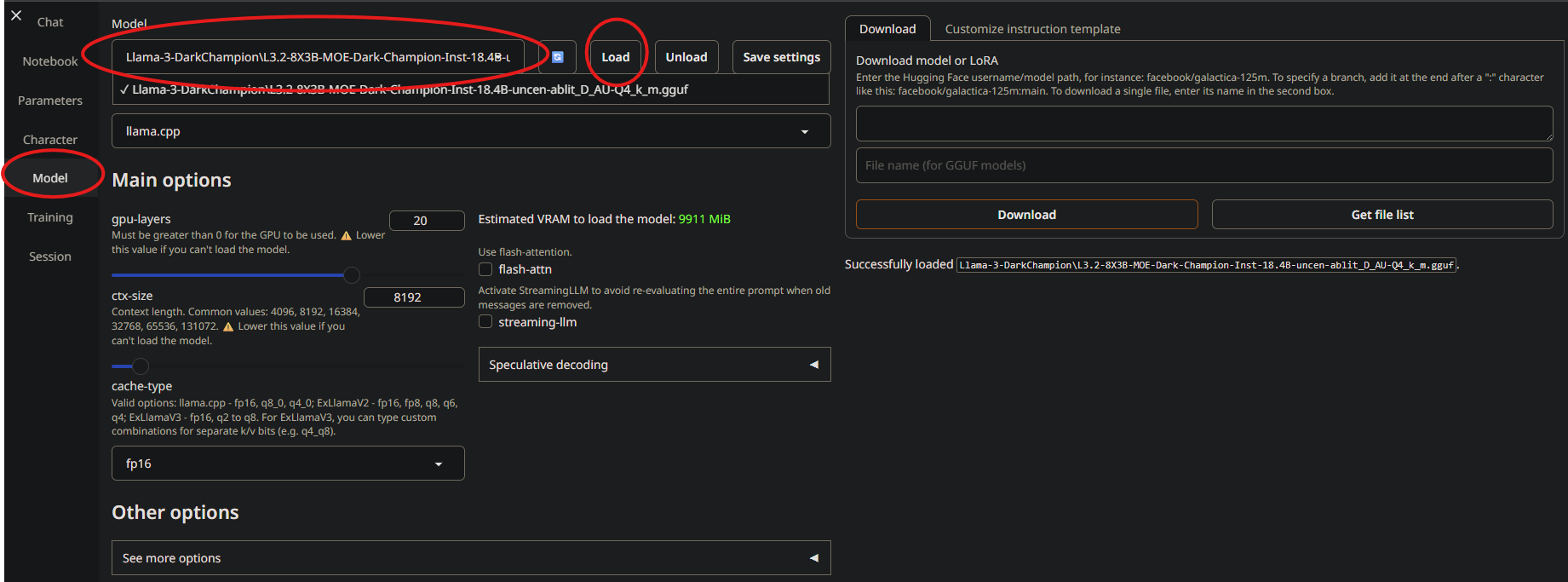
And that’s it!
Next Steps
Check out these notes: