Systems Involved with Memory
EchoForge
Memory Ingestion
Also needs a system that for ContextWeave that…
- tags data with auto generated
elementfrom a pre-defined list of elements - auto-generate Shards that are very specific tags. They will be unique
ContextWeave
Memory Retrieval
Through Filtering + RAG pipeline
ContextStore
Memory Storage
Chat System
Need to have context of chats.
Layers of memory by order:
- Current Chat → always persists session memory and is part of context
- Recent
nChat → Num of included sessions can be adjusted - Chat Tags → filter through all user chats and include
nrelated Chats based on tagging - IDEA: Chat sessions can be ingested as specific
elements(memories) automatically so that you can RAG over them. You can ask the user if they want to do so before deleting the chat. And also give them the option to “sync” the chat
RAM Controller
Reads metadata and selects subsets to inject as context
CONTEXT MANAGER?
this could be the ui part for element (memory) management. Either way there will be a way for users to manage their memories and that system will interact with Memory
Memory Schema
ContextStore is all based on elements which are basically memories that are stored in the ContextStore. elements are combined with a prompt to give the LLM context when prompting through ContextStore.
Retrieval will be based on 2 layers:
- Filtering on Tags/Categories
- Filtering on Shards (will explain/expand later)
- RAG filtering
We will also include in the context by default:
- Relevant Chat data
- Memories chosen by RAM System
A memory(element) contains the following:
- Tags/Categories: Human readable filters used for labeling
- Types
- Pre-defined: System categories like “career” or “relationship”
- User-defined: Freeform tags manually entered/curated by the user
- System-suggested: Use LLM to suggest tags like “imposter syndrome”
- Used for
- Symbolic filtering, often first pass of retrieval filter
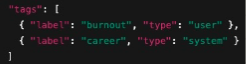
- Symbolic filtering, often first pass of retrieval filter
- Types
- Shards: Groupings across time, meaning, etc. for retrieval and context weaving. These are custom.
- Types
- Semantic
- Emotional
- Personas
- Temporal
- Conversational
- Event-Based
- Each
memorycan belong to many shards
- Types
- Metadata: Used for internal state tracking. The RAM system works using metadata.
- Here’s what it might look like:
"metadata": {
"created_at": "2025-05-03T18:01:002",
"source": "manual_entry",
"author": "user",
"pinned": false
}- Embeddings: Core of semantic searching and clustering
- Stored as a VECTOR
- Includes a MODEL_VERSION of the model that created the embeddings for provenance.
- MongoDB stores an “embedding_id”, for instance “vector_entry_1” → You generate an embedding for the memory like “
embedding=embed("I like yogurt")” → Add and store that embedding in a vector DB